MixDQ: Memory-Efficient Few-Step Text-to-Image Diffusion Models with Metric-Decoupled Mixed Precision Quantization
MixDQ: Memory-Efficient Few-Step Text-to-Image Diffusion Models with Metric-Decoupled Mixed Precision QuantizationDiffusion models have achieved significant visual generation quality. However, their significant computational and memory costs pose challenge for their application on resource-constrained mobile devices or even desktop GPUs. Recent few-step diffusion models reduces the inference time by reducing the denoising steps. However, their memory consumptions are still excessive.
The Post Training Quantization (PTQ) replaces high bit-width FP representation with low-bit integer values (INT4/8) , which is an effective and efficient technique to reduce the memory cost. However, when applying to few-step diffusion models, existing quantization methods face challenges in preserving both the image quality and text alignment.
To address this issue, we propose an mixed-precision quantization framework - MixDQ. Firstly, We design specialized BOS-aware quantization method for highly sensitive text embedding quantization. Then, we conduct metric-decoupled sensitivity analysis to measure the sensitivity of each layer. Finally, we develop an integer-programming-based method to conduct bit-width allocation.
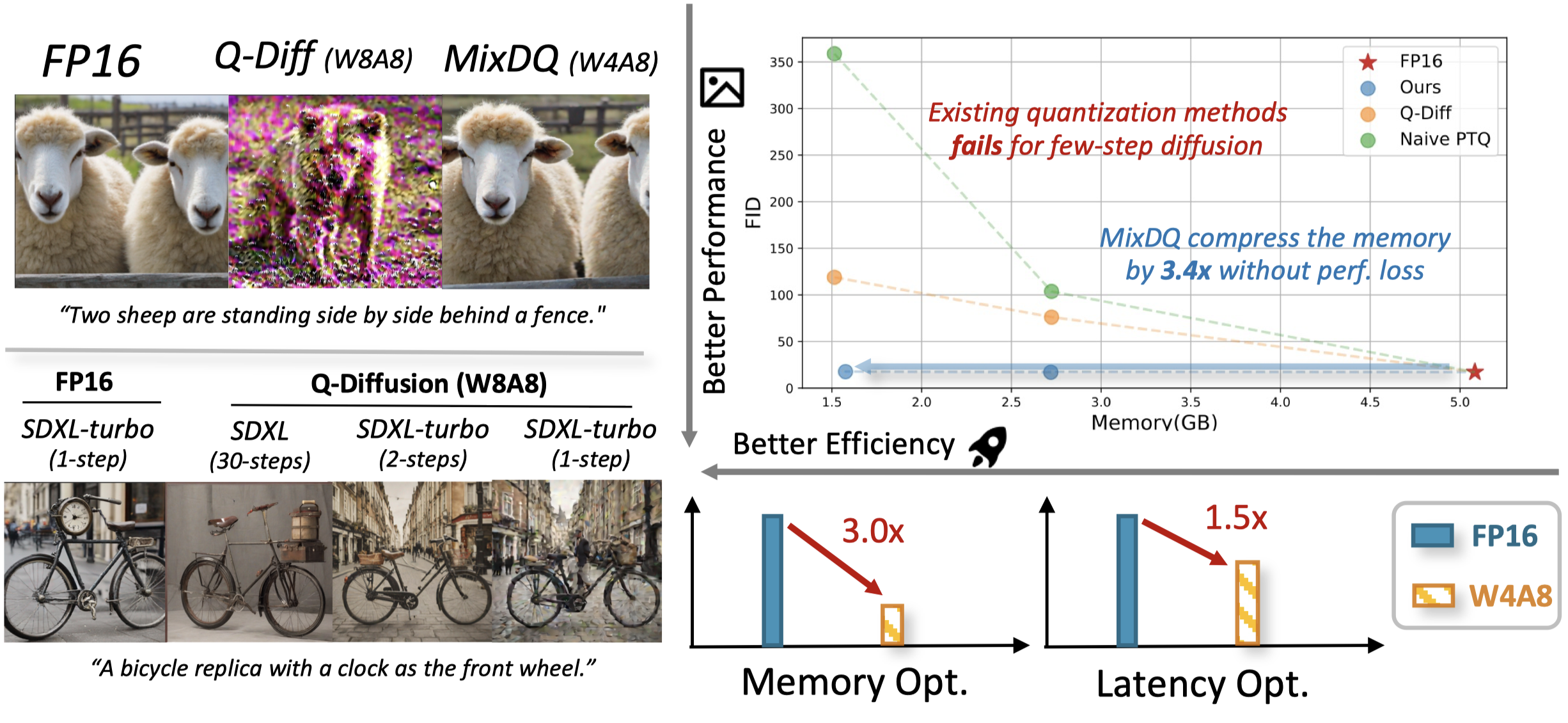
While existing quantization methods fall short at W8A8, MixDQ could achieve W8A8 without performance loss, and W4A8 with negligible visual degradation. Compared with FP16, we achieve 3-4x reduction in model size and memory cost, and 1.45x latency speedup.
We empirically discover that the few-step diffusion models are more sensitive to quantization compared with multi-step diffusion models, and prior diffusion quantization methods faces challenges. Q-diffusion W8A8 quantized model faces severe quality degradation under few-steps. Also, even with multi-step model, quantization harms the text-image alignment.

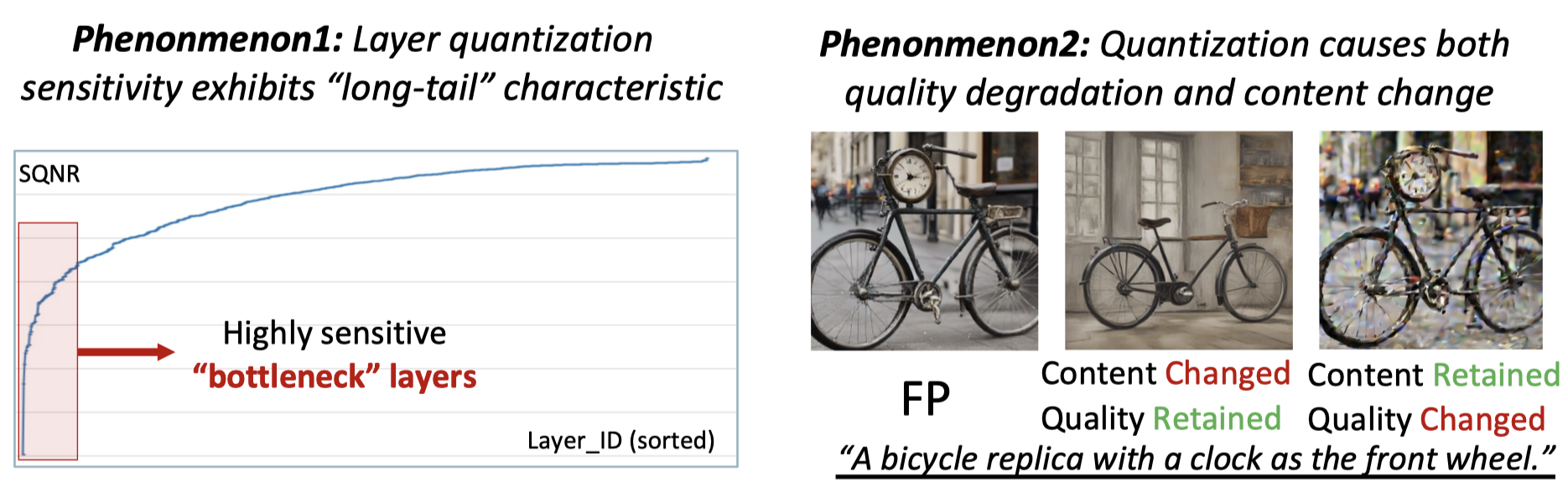
We conduct preliminary experiments to delve into the reasons for quantization failure, and discover two insightful findings: (1) The quantization are "bottlenecked" by some highly sensitive layers. (2) Quantizing different part of the model affects generated image quality and content repsectively.
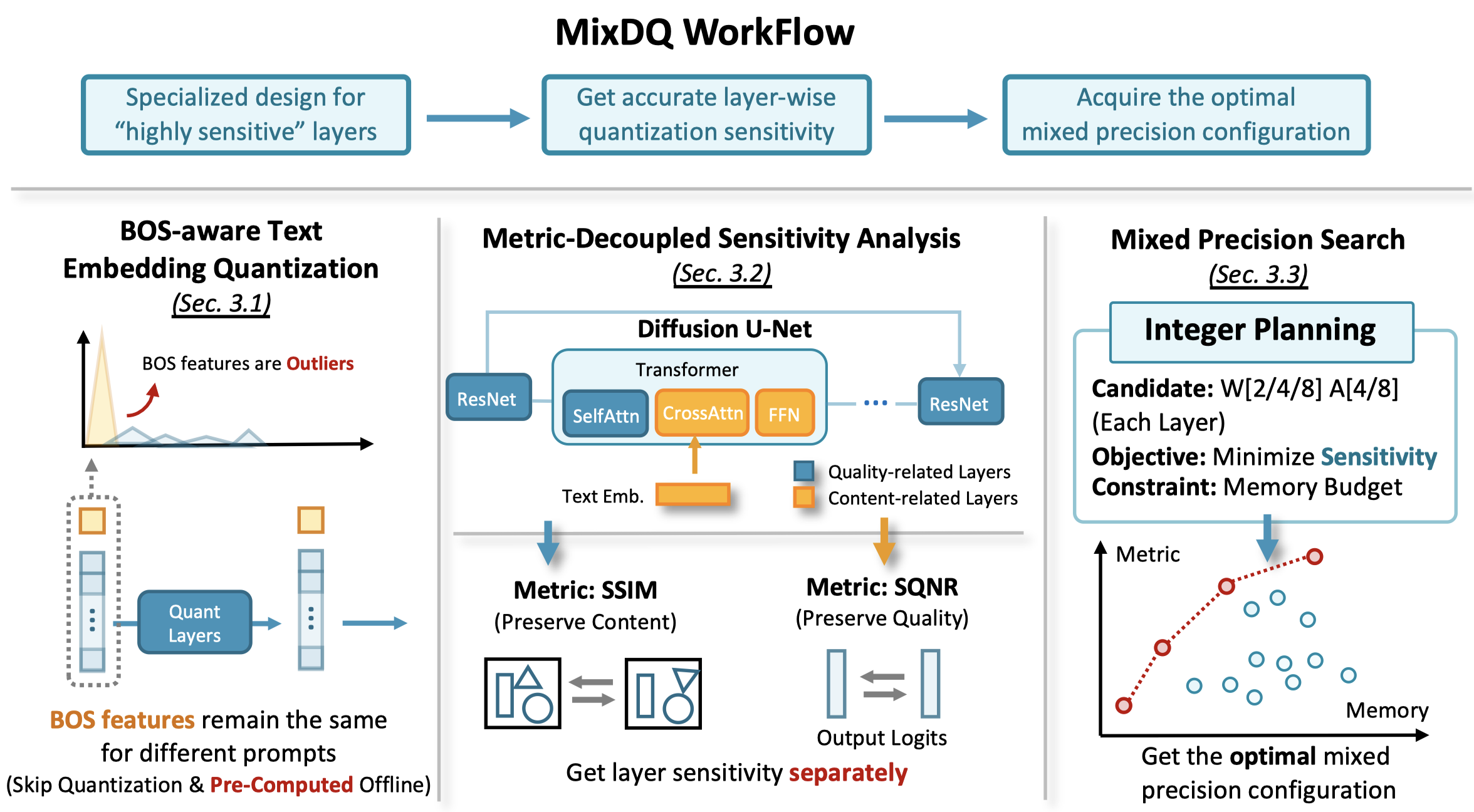
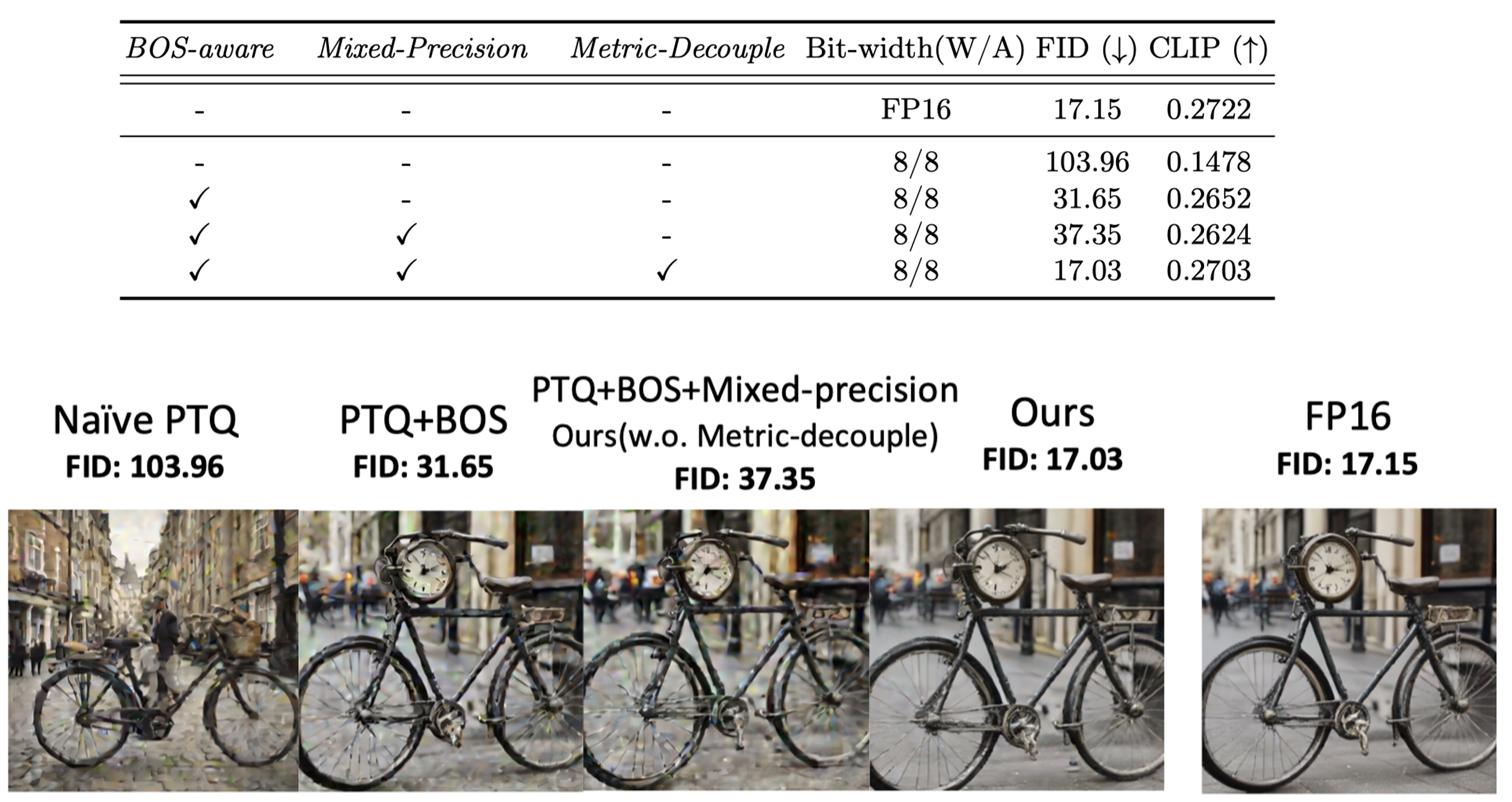
We discover that the 1st token of the CLIP text embedding is the outlier that hinders quantization. Further, we notice that the first token is the Begin-Of-Sentence (BOS) token that remains the same for different prompts. Therefore, we could pre-compute it offline and skip its quantization.
When simply remaining the layers that causes the most quantization error FP16, we discover that the generated image still faces quality degradation, denoting existing quantization sensitivity analysis's accuracy needs improving. Inspired by the quantization's affects on image quality and textual alignmet, we design a Metric-Decoupled Sensitivity Analysis method. We seperate the layers into 2 groups, and conduct sensitivity analysis with distinct metrics repsectively for them.
After acquiring the quantization sensitivity, we formulate the bit-width allocation problem into an integer-programming method, and adopt off-the-shelf solver to efficiently solve them.
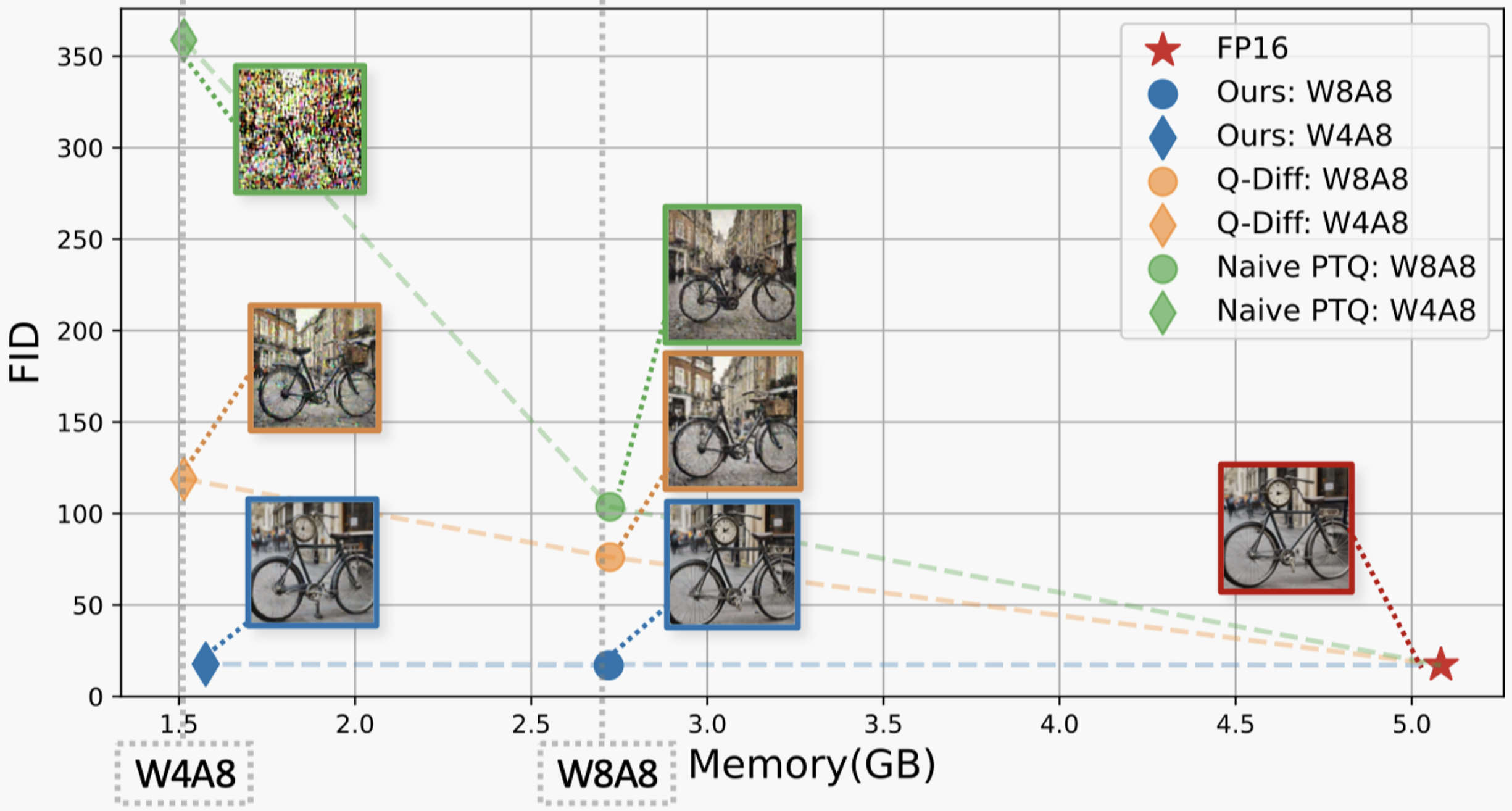
We present the performance of MixDQ on COCO text-to-image task. We choose multiple metrics that reflect different aspect of the generated images. The FID for image fidelity (quality), the CLIPScore for textual alignment, and the ImageReward for human preference. MixDQ could achieve W8A8 without performance loss. With just 0.1/0.5 FID increase, MixDQ could achivee W5A8/W4A8. At the same time, the baseline quantization methods fall short at W8A8 (60 FID increase, negative ImageReward).
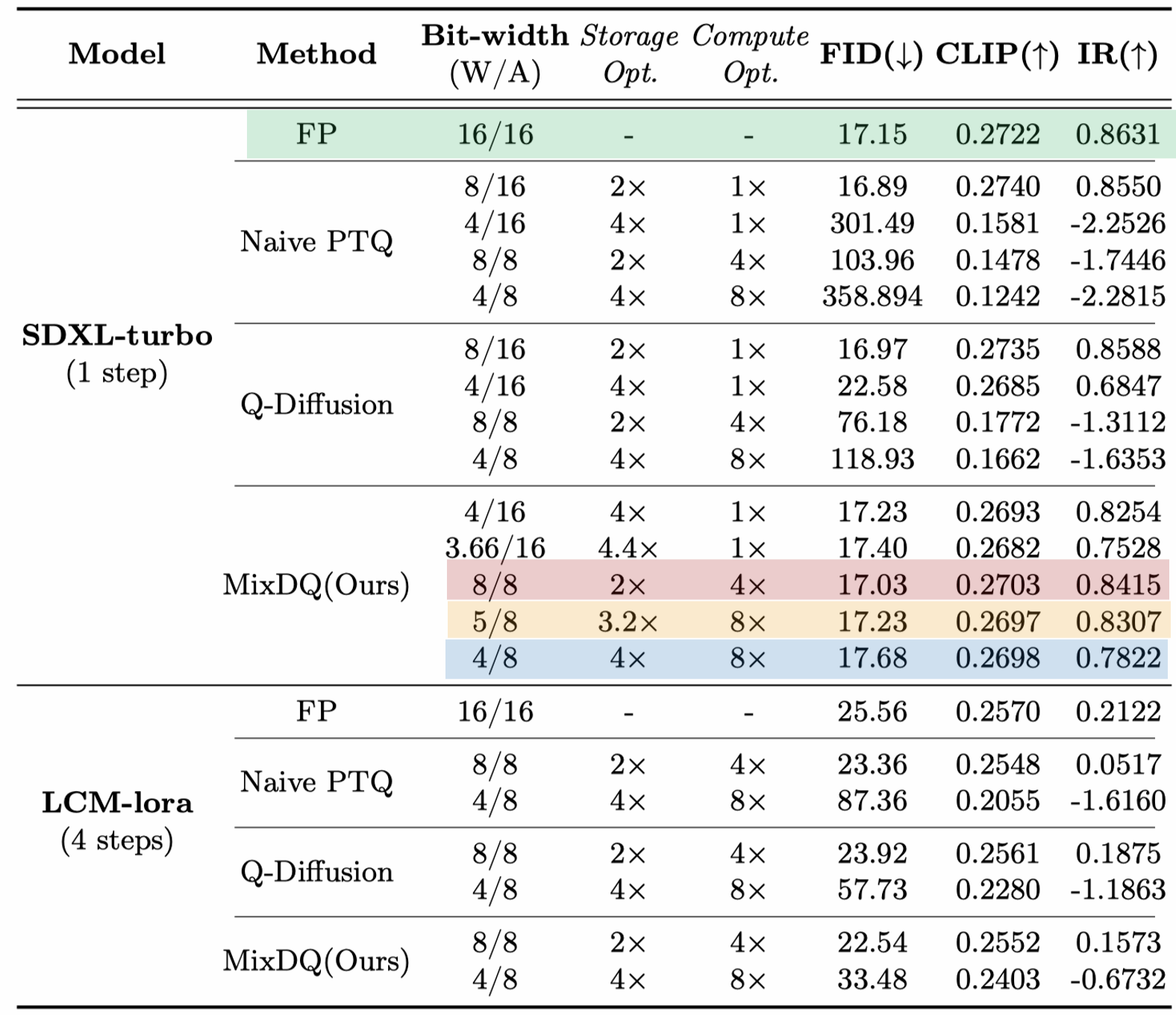
We present some qualitative results that relates the statistical metric values with generated image. As could be seen, compared with Q-Diffusion and naive minmax quantization. MixDQ-W4A8 could generate image nearly identical with the FP image, while other methods fail to produce readable image for W8A8.
We test the efficiency improvement of MixDQ quantization with hardware profiling. As could be seen, MixDQ could achive 3-4x memory compression rate, and 1.4-1.6x latency speedup with W4A8.
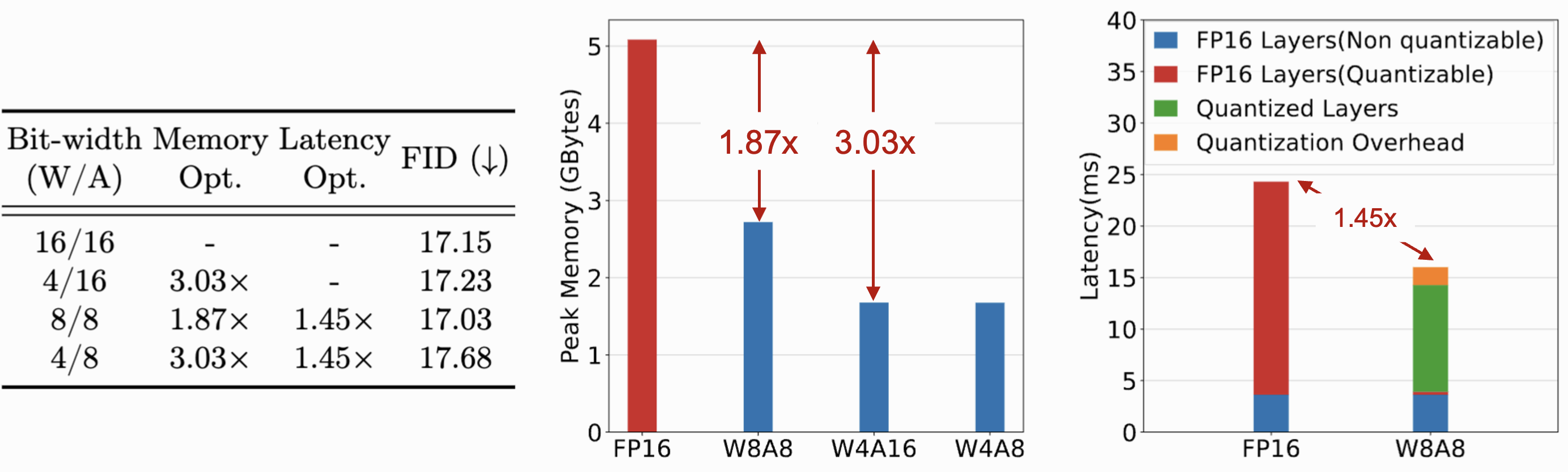
We implement efficient INT8 GPU kernel implementation for practical hardware acceleration on GPU. We present MixDQ model's huggingface pipeline, which could be efficiently called with a few lines of codes. It achives 2x model size reduction, and 1.45x end-to-end latency speedup.

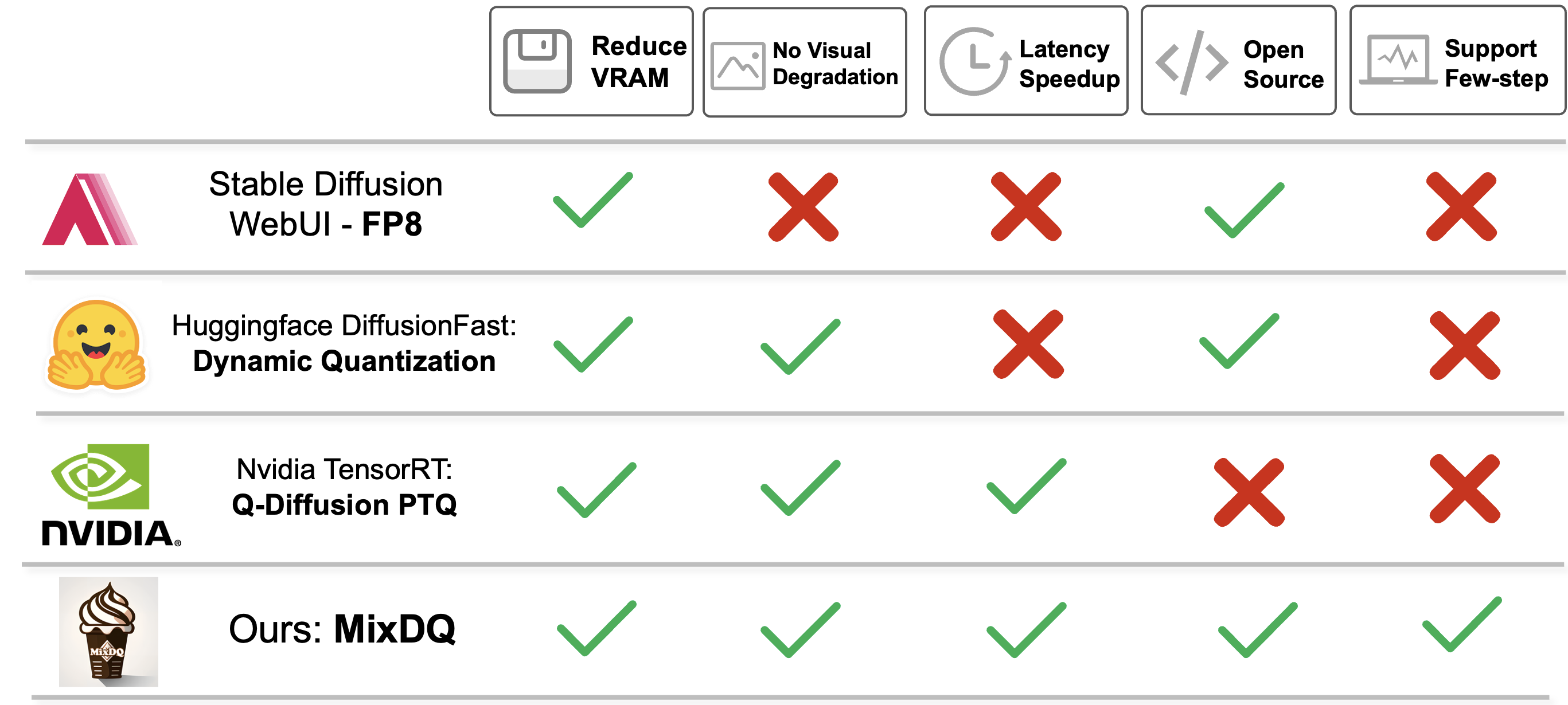
Compared with other existing diffusion model quantization tools. Only the closed-form TensorRT INT8 implementation achieves practical latency speedup. MixDQ is the 1st to achieve practical memory and latency optimization for few-step diffusion models, enabling "tiny and fast" image generation.

@misc{zhao2024mixdq,
title={MixDQ: Memory-Efficient Few-Step Text-to-Image Diffusion Models with Metric-Decoupled Mixed Precision Quantization},
author={Tianchen Zhao and Xuefei Ning and Tongcheng Fang and Enshu Liu and Guyue Huang and Zinan Lin and Shengen Yan and Guohao Dai and Yu Wang},
year={2024},
eprint={2405.17873},
archivePrefix={arXiv},
primaryClass={cs.CV}
}