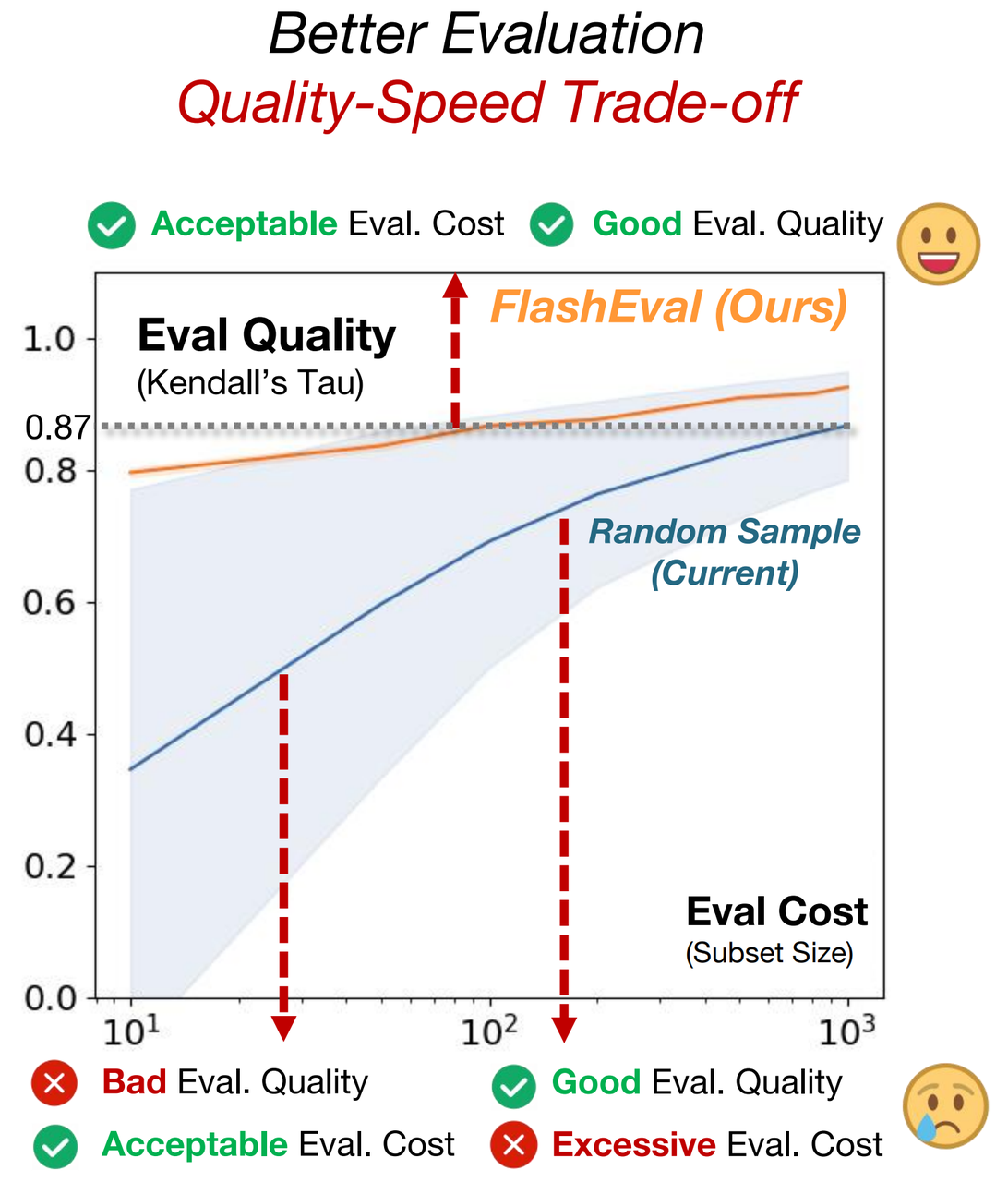
In recent years, there has been significant progress in the development of text-to-image generative models. Evaluating the quality of the generative models is one essential step in the development process. Unfortunately, the evaluation process could consume a significant amount of computational resources, making the required periodic evaluation of model performance (e.g., monitoring training progress) impractical.
Therefore, we seek to improve the evaluation efficiency by selecting the representative subset of the text-image dataset. We systematically investigate the design choices, including the selection criteria (textural features or image-based metrics) and the selection granularity (prompt-level or set-level). We find that the insights from prior work on subset selection for training data do not generalize to this problem, and we propose FlashEval, an iterative search algorithm tailored to evaluation data selection.
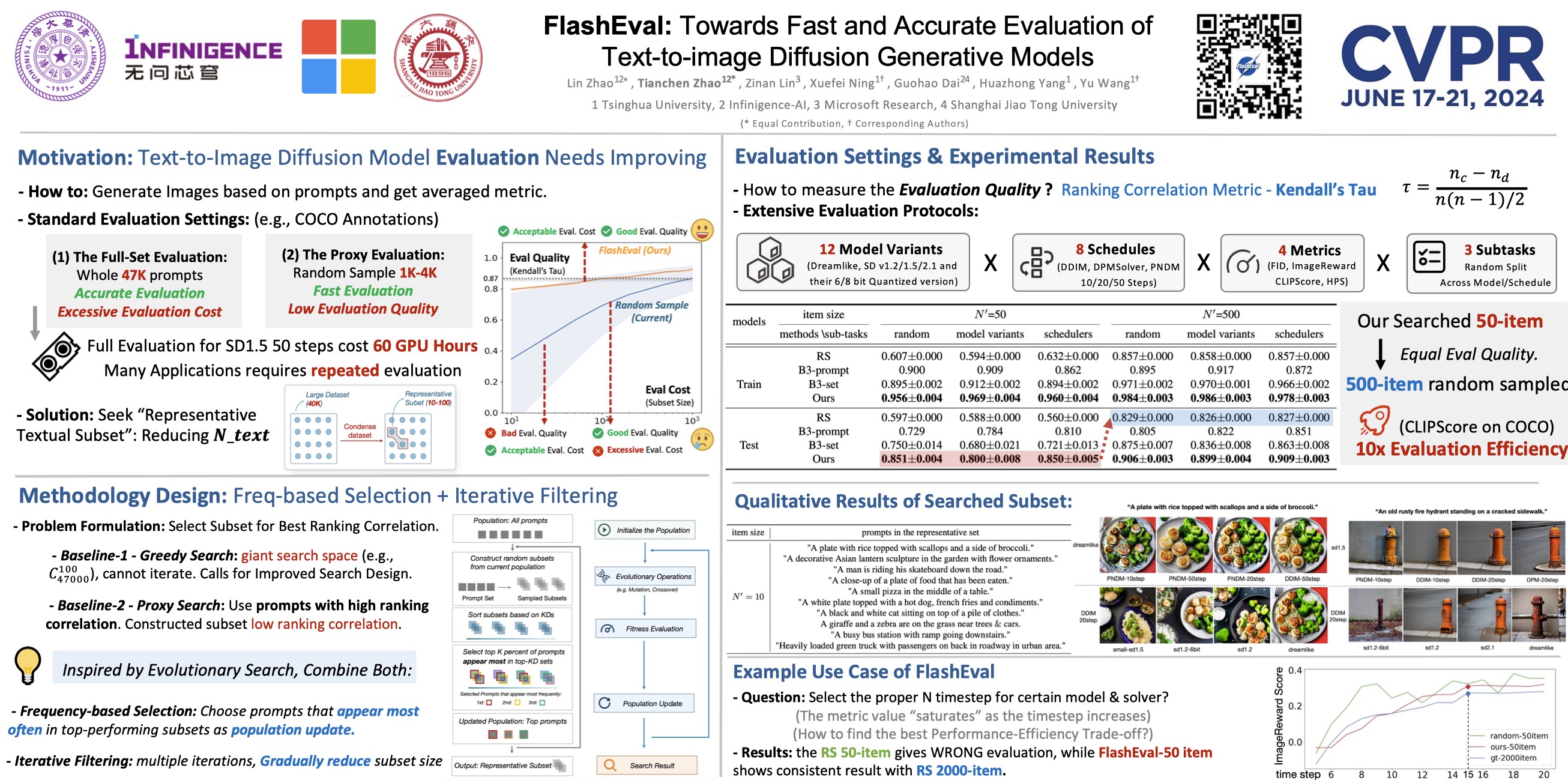
We demonstrate the effectiveness of FlashEval on ranking diffusion models with various configurations, including architectures, quantization levels, and sampler schedules on COCO and DiffusionDB datasets. Our searched 50-item subset could achieve comparable evaluation quality to the randomly sampled 500-item subset for COCO annotations on unseen models, achieving a 10x evaluation speedup. We release the condensed subset of these commonly used datasets to help facilitate diffusion algorithm design and evaluation, and open-source FlashEval as a tool for condensing future datasets, accessible at https://github.com/thu-nics/FlashEval
When evaluating the text-to-image generative models. The common practice is to iterate through a textual dataset (e.g., COCO annotations, DiffusionDB), and calculate the metric scores for generated images to represent the model. However, these textual datasets often exhibits a large size (47K for COCO, 15K for PicScore). A complete evaluation of SD1.5 model with DDIM 50 steps on the whole COCO cost 60 GPU hours (RTX3090)
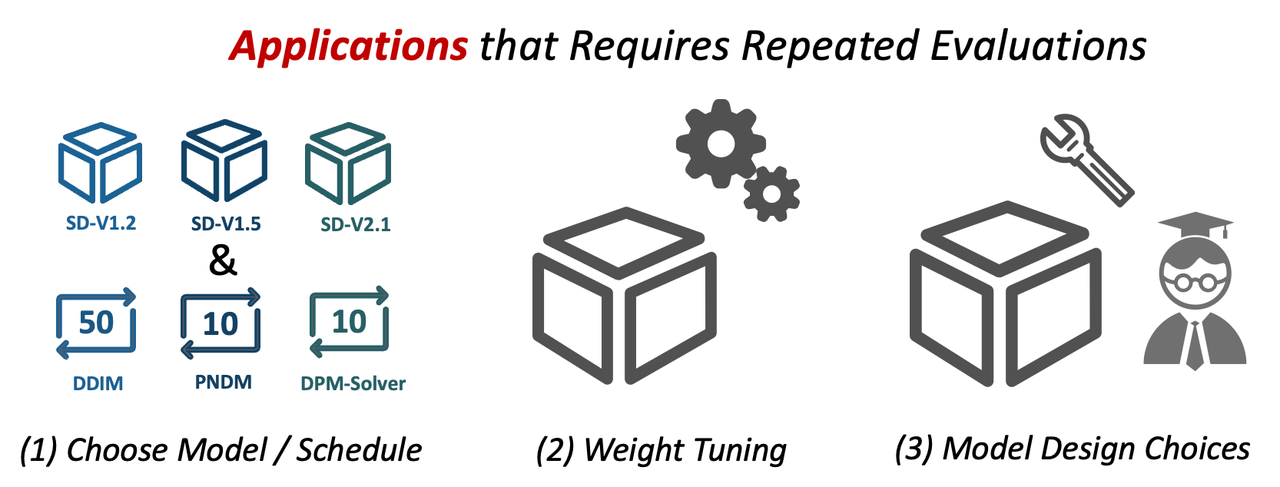
However, for both model training and algotithm design, many applications require repeated evaluation. For instance, choosing proper model and schedule, finetuning the model, or make some model design choices. In these applications, the evaluation cost is the major bottleneck for development.
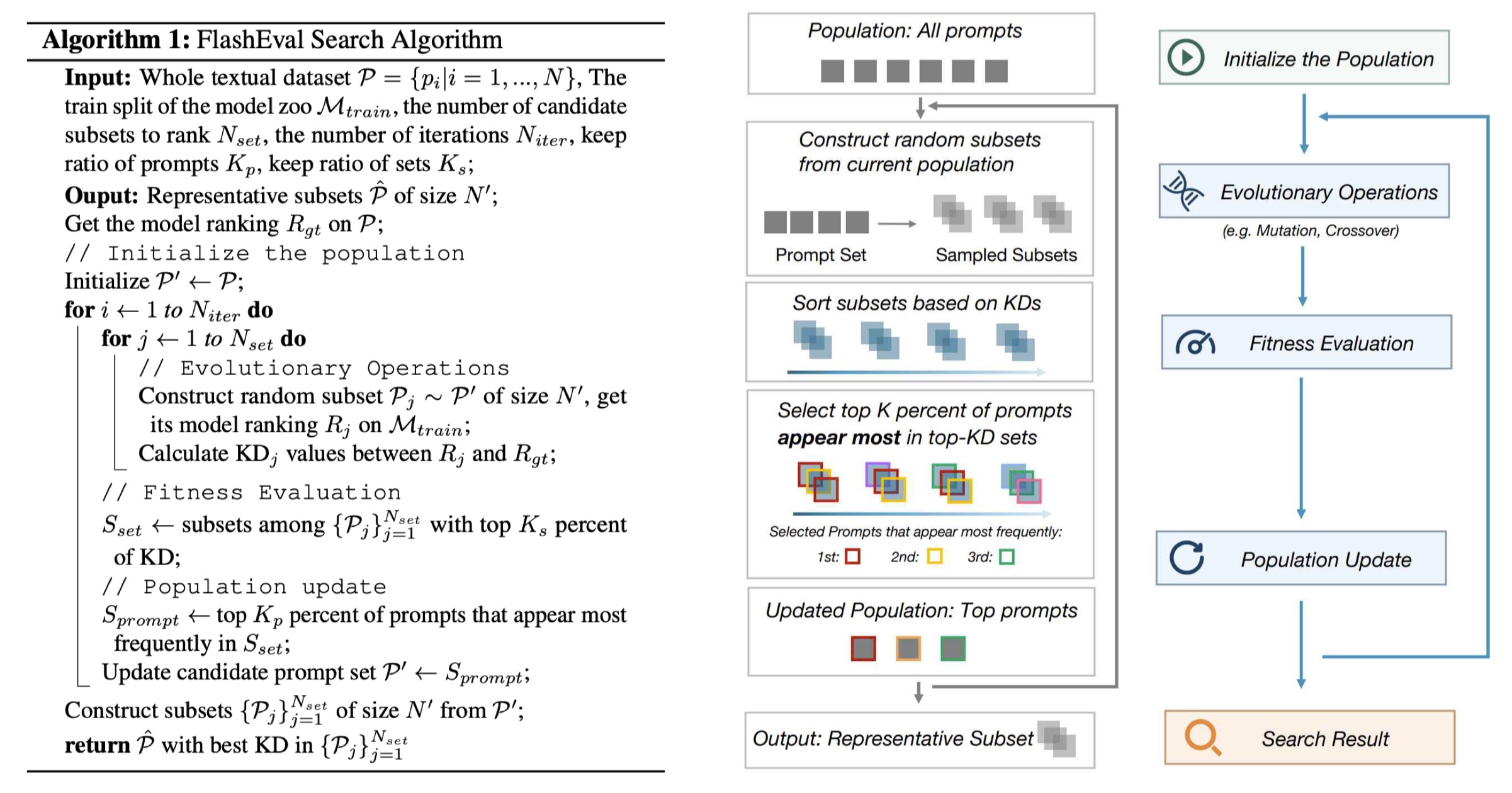
We discover that simply choosing the prompts or subsets with highest KD, does not show satisfying generalization ability, and design an iterative filtering algorithm.
We discover that the prompts with standalone higher KD, when combined together, does not necessarily show higher evaluation quality. After further investigation, we discover that the prompts that appear more frequently in top-performing subsets show better correlation with the evaluation quality.
We evaluate FlashEval on multiple datasets (COCO, DiffusionDB), multiple metrics (FID, CLIP, Aesthetic, ImageReward), and diverse model zoo (including 78 models, covering 12 model architecture and weights, and 8 different solvers). To verify the generalization ability of the searched subset, we design 3 subtasks by spliting the model zoo into 2 halves, and conduct searching on one half, and test on the other half. The tasks are: random split, across model variants, and across schedules.

We present the evaluation quality for different settings. FlashEval searched subset demonstrate consistent superior performance compared with baseline methods. The FlashEval acquired 50-item subset achieves similar performance with 500-item random-sampled subset.
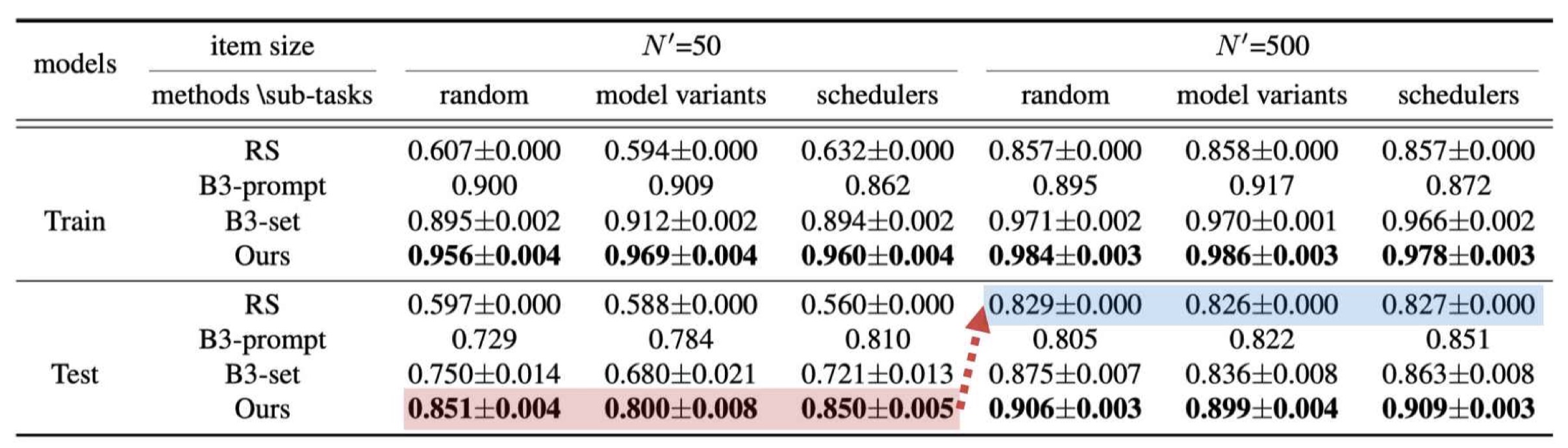
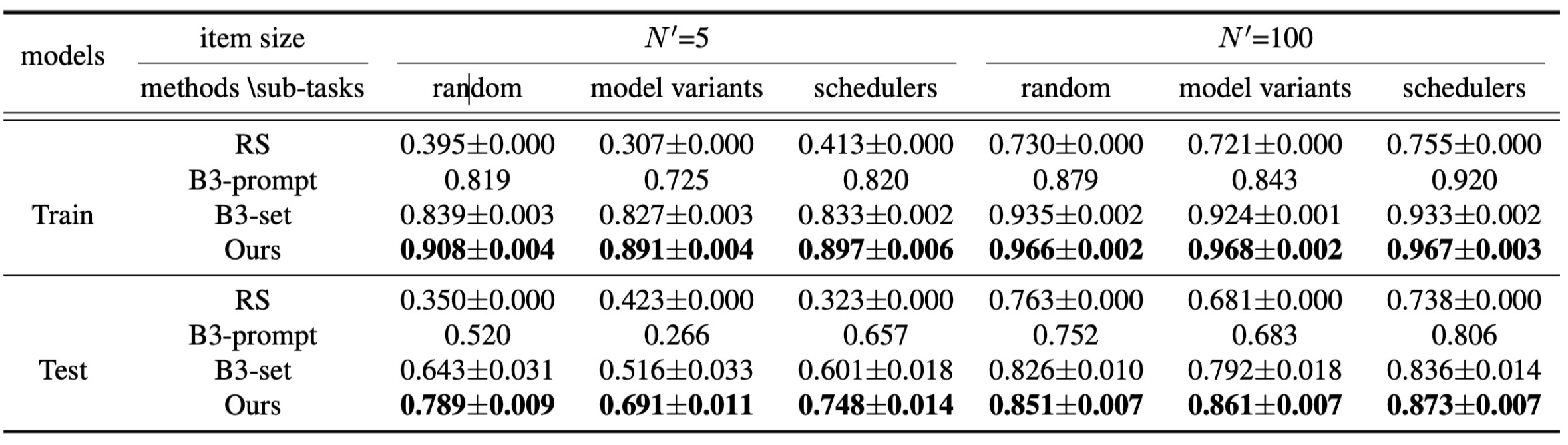
Similar results are also witnessed on diffusionDB dataset.
@article{zhao2024flasheval,
title={FlashEval: Towards Fast and Accurate Evaluation of Text-to-image Diffusion Generative Models},
author={Zhao, Lin and Zhao, Tianchen and Lin, Zinan and Ning, Xuefei and Dai, Guohao and Yang, Huazhong and Wang, Yu},
journal={arXiv preprint arXiv:2403.16379},
year={2024}
} FlashEval: Towards Fast and Accurate Evaluation of Text-to-image Diffusion Generative Models
FlashEval: Towards Fast and Accurate Evaluation of Text-to-image Diffusion Generative Models