Poster

Video
Abstract
Voxel-based methods have achieved state-of-the-art performance for 3D object detection in autonomous driving. However, their significant computational and memory costs pose a challenge for their application to resource-constrained vehicles.
While current efficient 3D perception methods mainly focus on "model-level redundancy". We discover that one reason for this high resource consumption is the presence of a large number of redundant background points in Lidar point clouds, resulting in "data-level spatial redundancy" in both 3D voxel and BEV map representation.
To address this issue, we propose an adaptive inference framework - Ada3D, which focuses on reducing the spatial redundancy to compress the model’s computational and memory cost. Ada3D adaptively filters the redundant input, guided by a lightweight importance predictor and the unique properties of the Lidar point cloud. Additionally, we maintain the BEV features’ intrinsic sparsity by introducing sparsity-preserving batch normalization.
With Ada3D, we achieve 40% reduction for 3D voxels and decrease the density of 2D BEV feature maps from 100% to 20% without sacrificing accuracy. Ada3D reduces the model computational and memory cost by 5×, and achieves 1.52× / 1.45× end-to-end GPU latency and 1.5× / 4.5× GPU peak memory optimization for the 3D and 2D backbone respectively.
Teaser
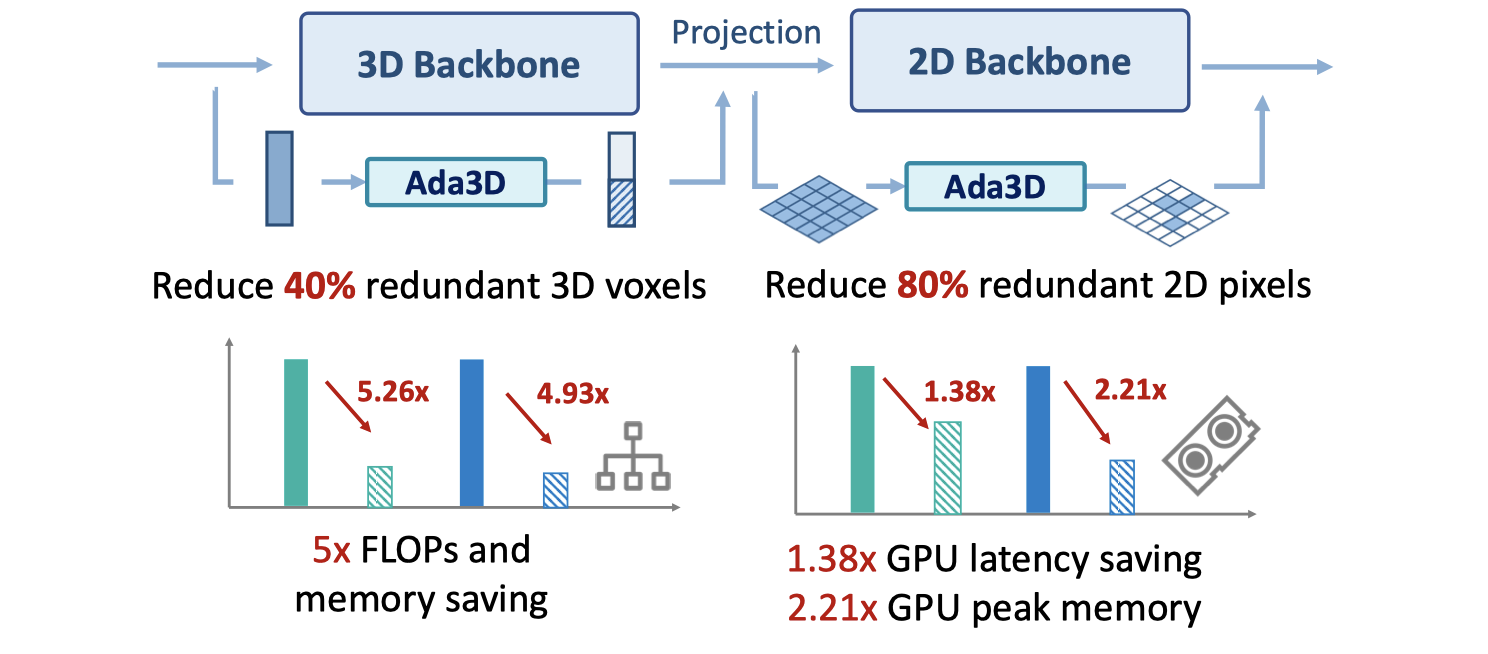
Motivation
Data-level Spatial Redundancy
Lidar-based 3D point cloud have many redundant background points (e.g., road surface and wall), and overdense points. The 2D BEV feature is projected from 3D sparse voxels, therefore a large portion of pixels in BEV are background zero features. We conduct oracle experiments to verify the spatial redundancy. Randomly dropping 30% input voxels result in less than 0.5 mAP loss, Dropping 70% voxels out of ground-truth bounding box incurs negligible performance loss.

Methodology
The overall framework of Ada3D consists of 3 key components.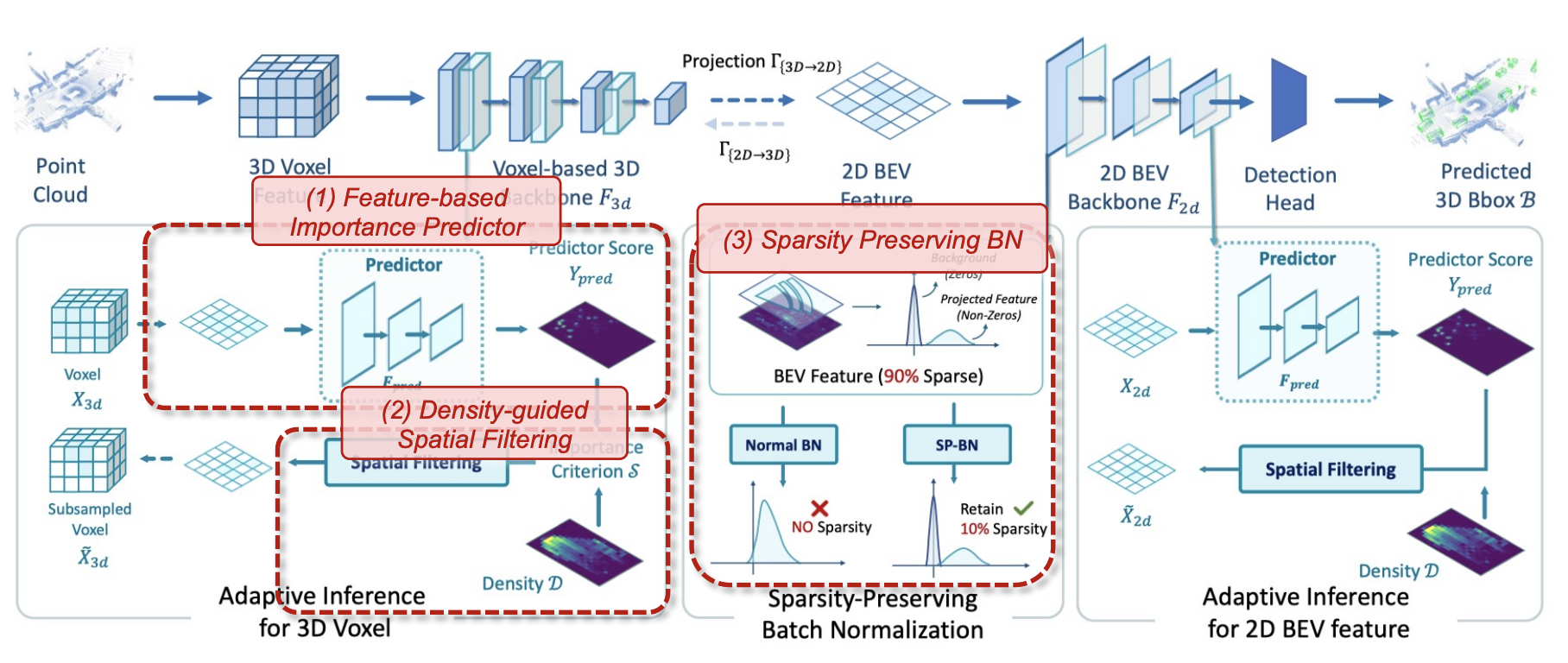
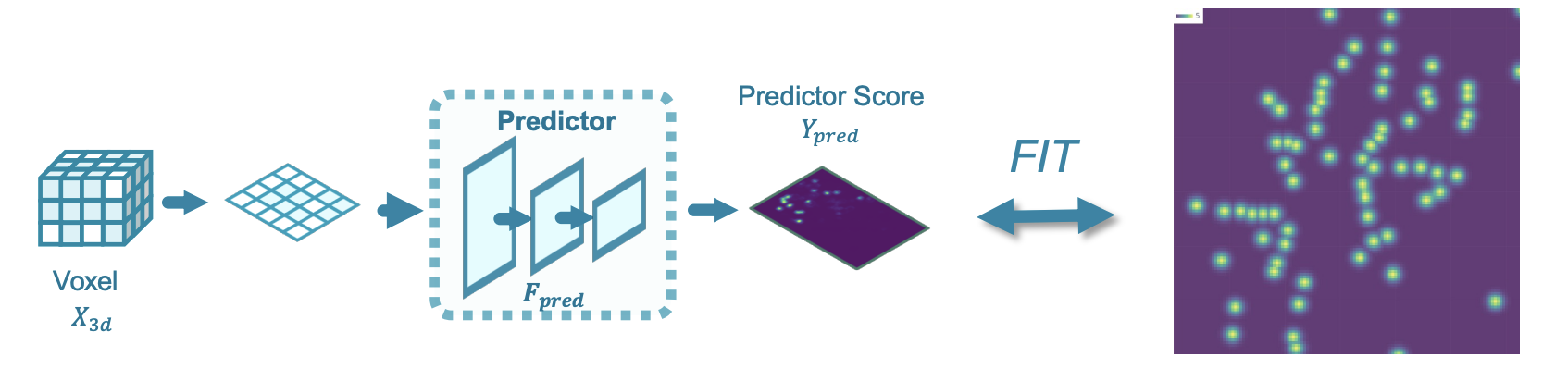
Importance Predictor
We design a lightweight shared BEV space importance predictor that maps the input feature to pixel-wise relative importance. It's trained to fit the center-based heatmap.
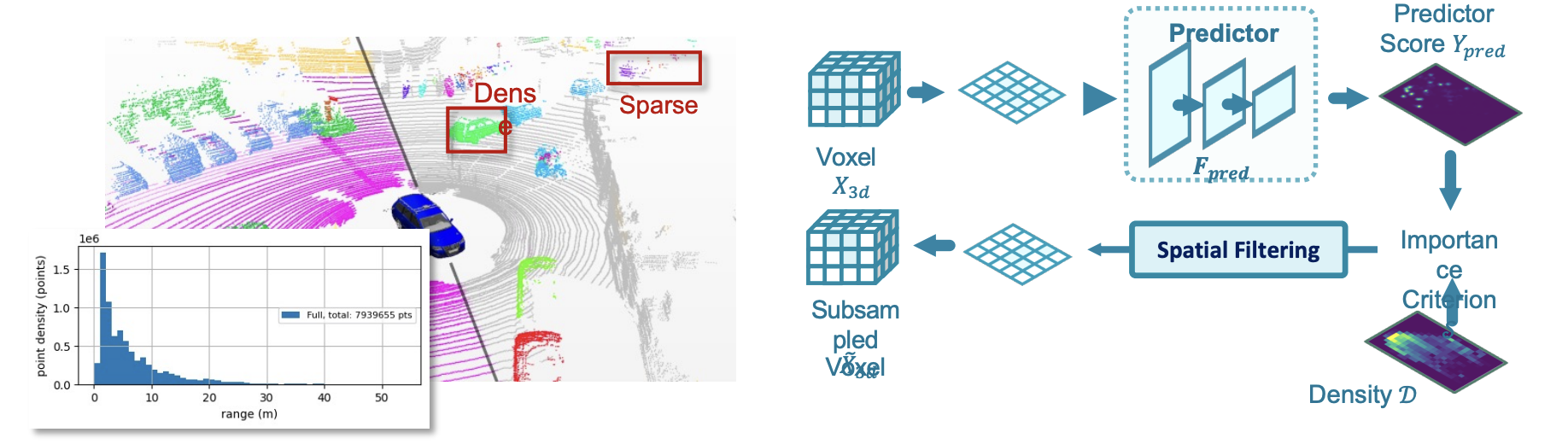
Density-guided Spatial Filtering
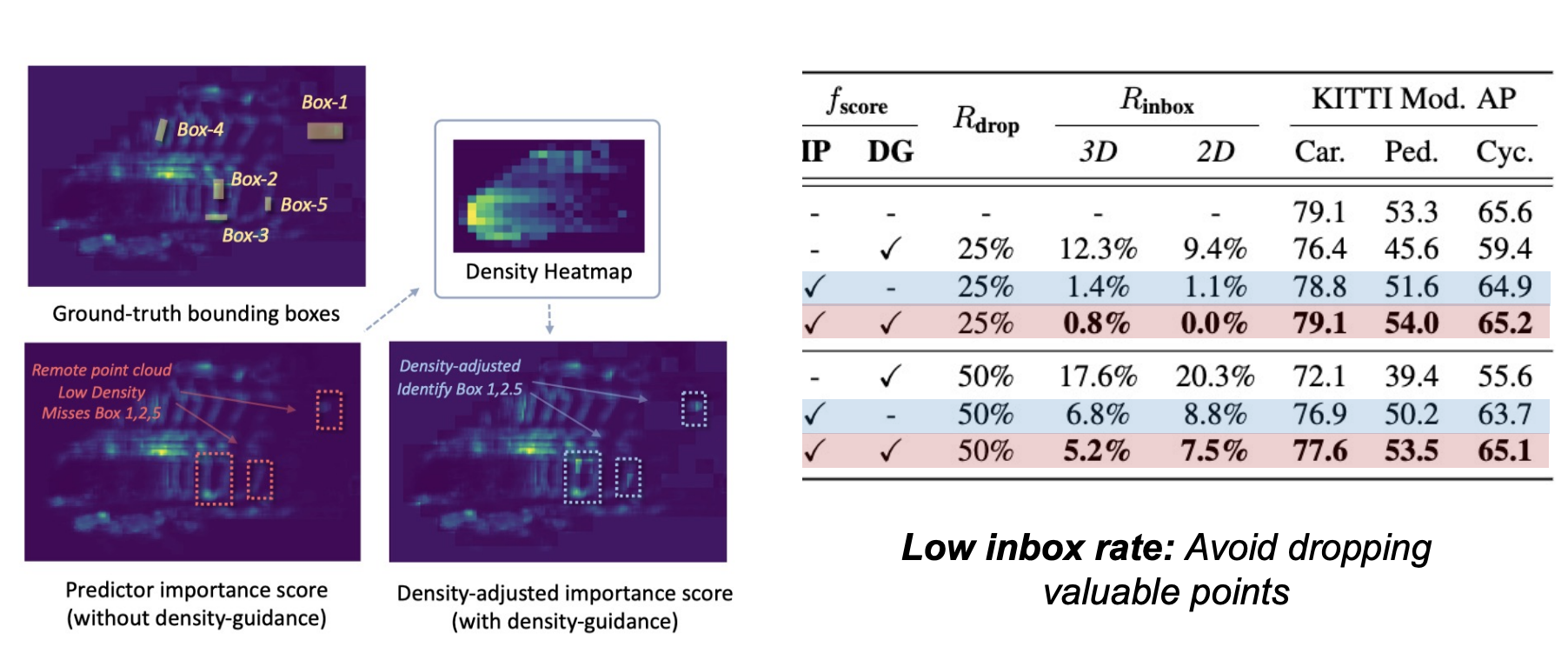
Lidar point cloud has the special property of density imbalance. The point cloud closer to the sensor is denser while the remote parts are sparse. The predictor tends to produce larger prediction for local parts, to compensate it, We introduce density-guidance for spatial filtering decision.
Sparsity-preserving Batch Normalization
The 2D BEV feature have a large portion of zero features, thus having large sparsity. However, the sparsity is lost after the first batch normalization. Applying BN to nonzero elements only will violate the relative feature relation and brings traininig instability during finetuning. To preserve the sparsity for 2D feature map, we introduce the sparsity-preserving BN.
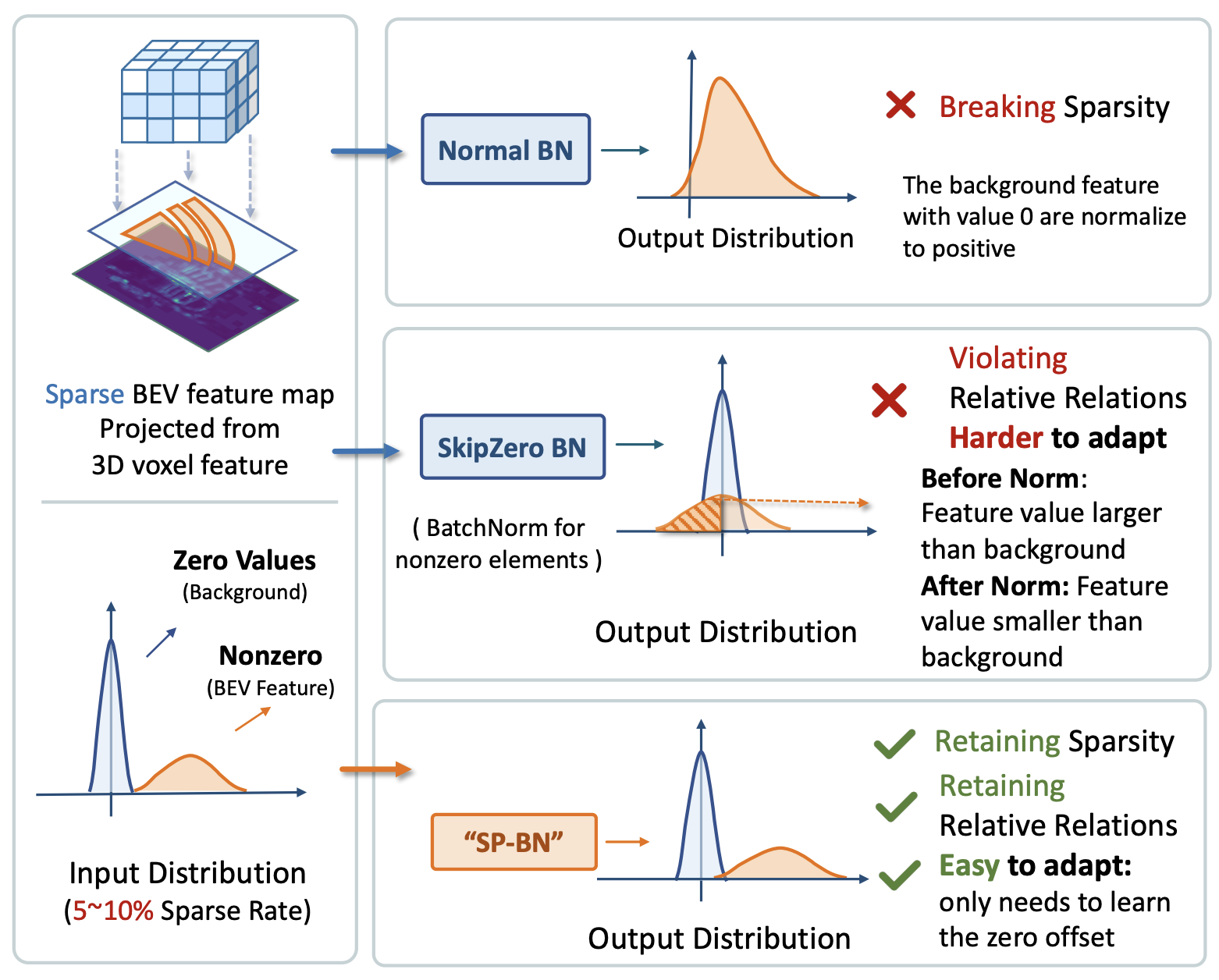
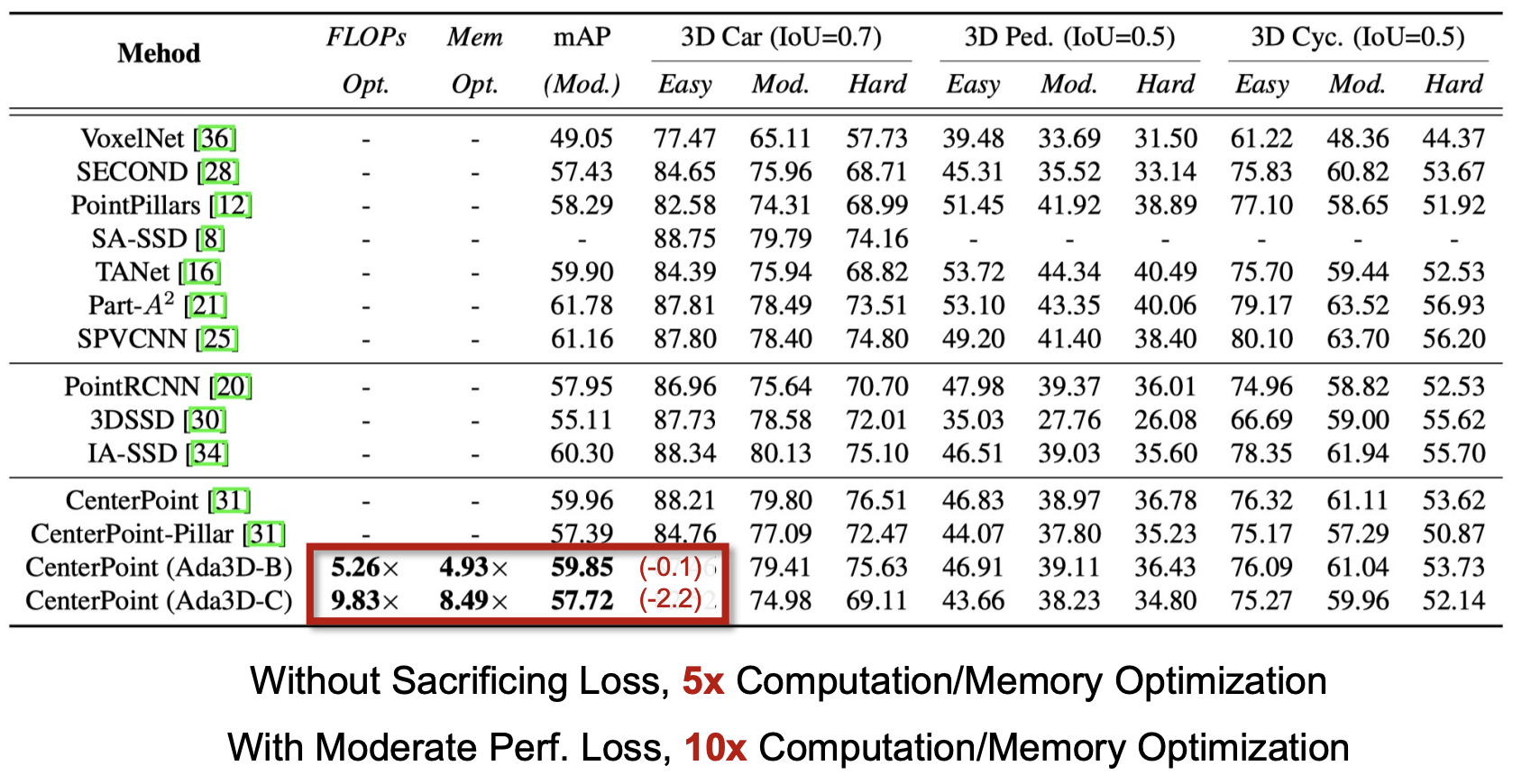
Experiments and Analysis
Performance
We presents the performance and model-level metrics on KITTI dataset:
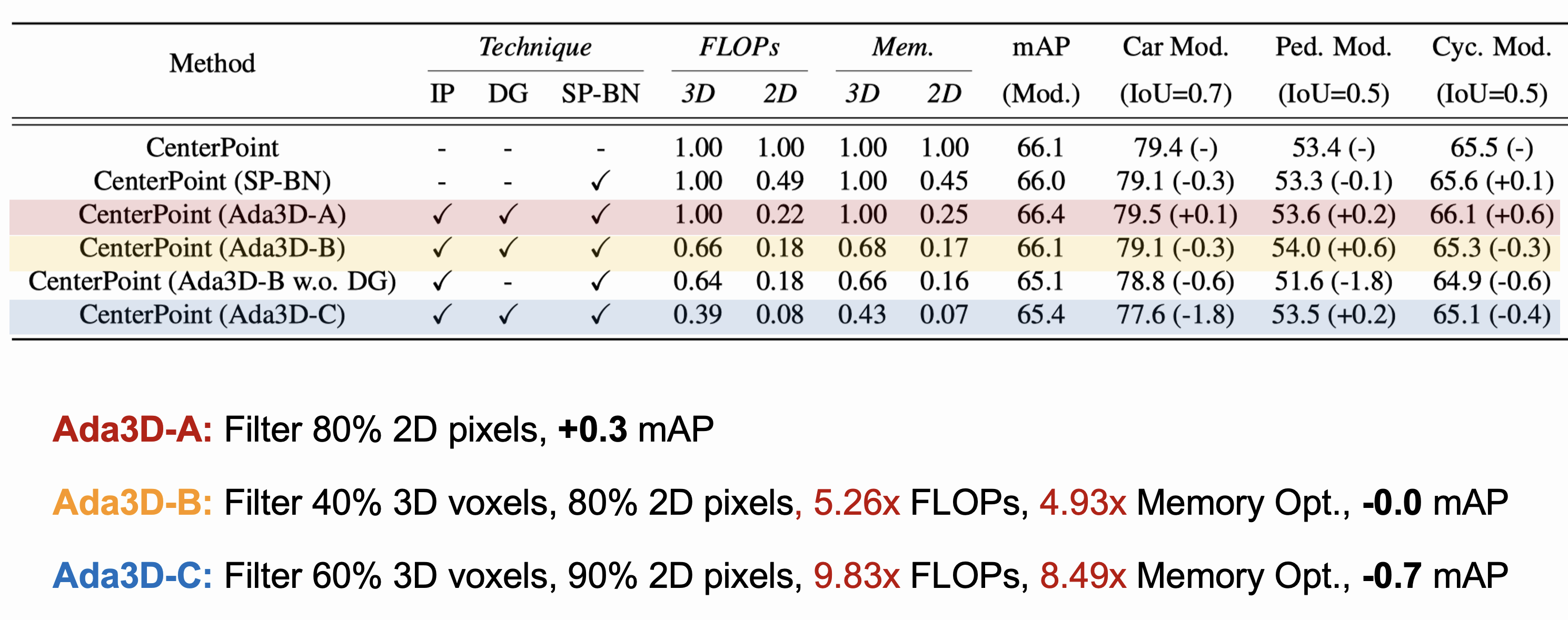
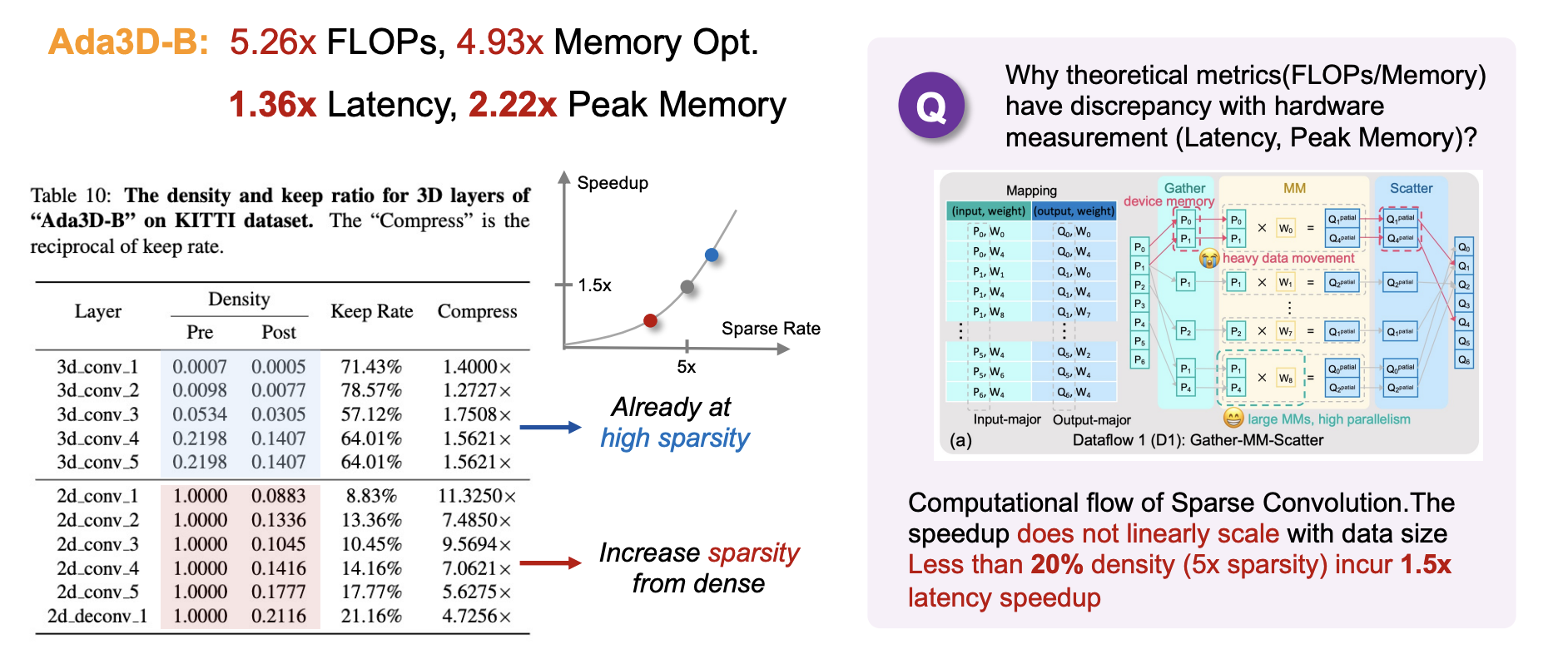
Hardware Experiments
We further conduct hardware experiments to demonstrate the actual speedup of Ada3D. The results are generated on RTX3090 with CUDA-11.1, SpConv v2.2.6 gather-scatter dataflow. We found that both the 3D and 2D part of 3D detectors require acceleration, and they have different acceleration rate.
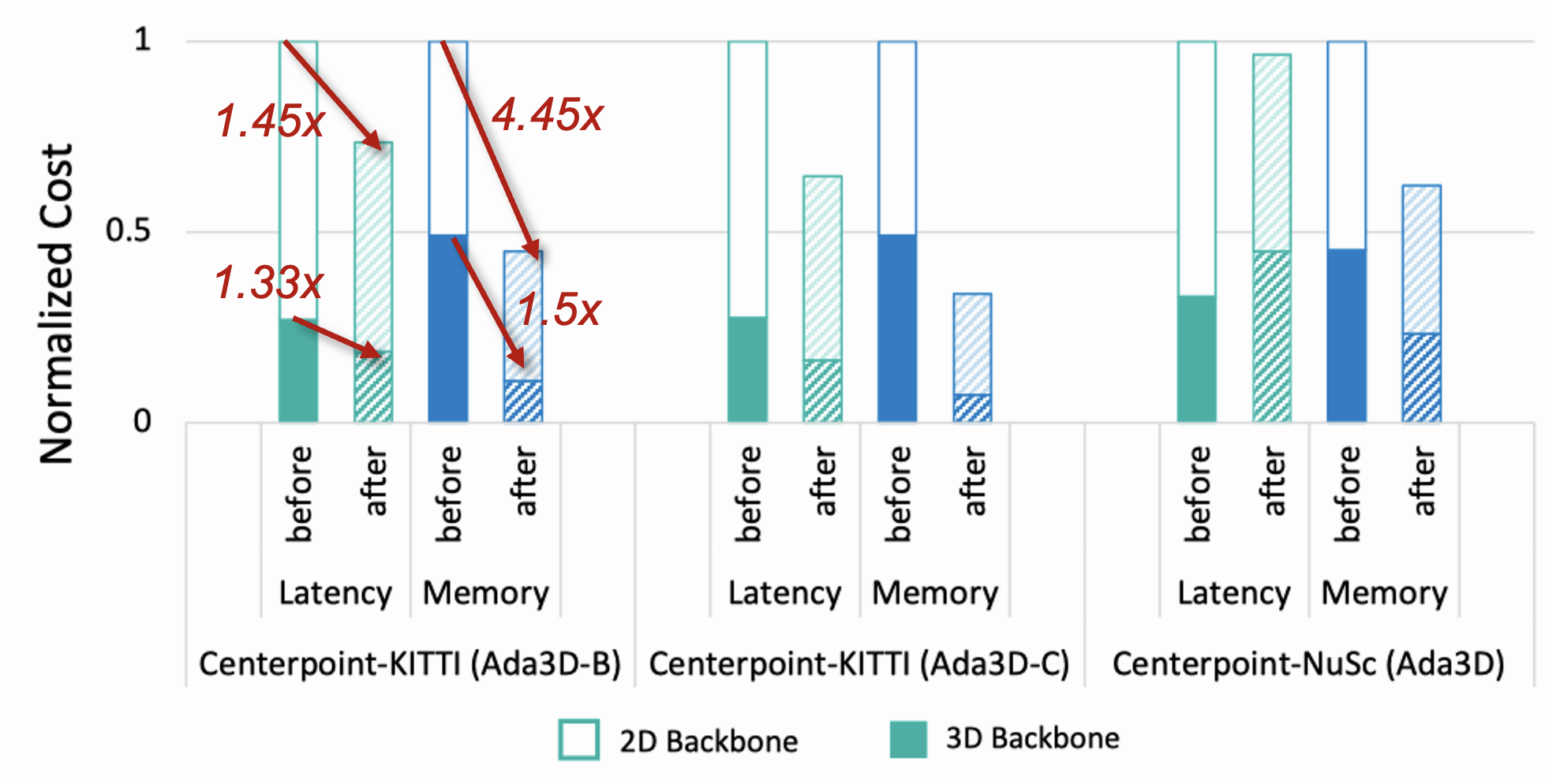
Qualitative Results
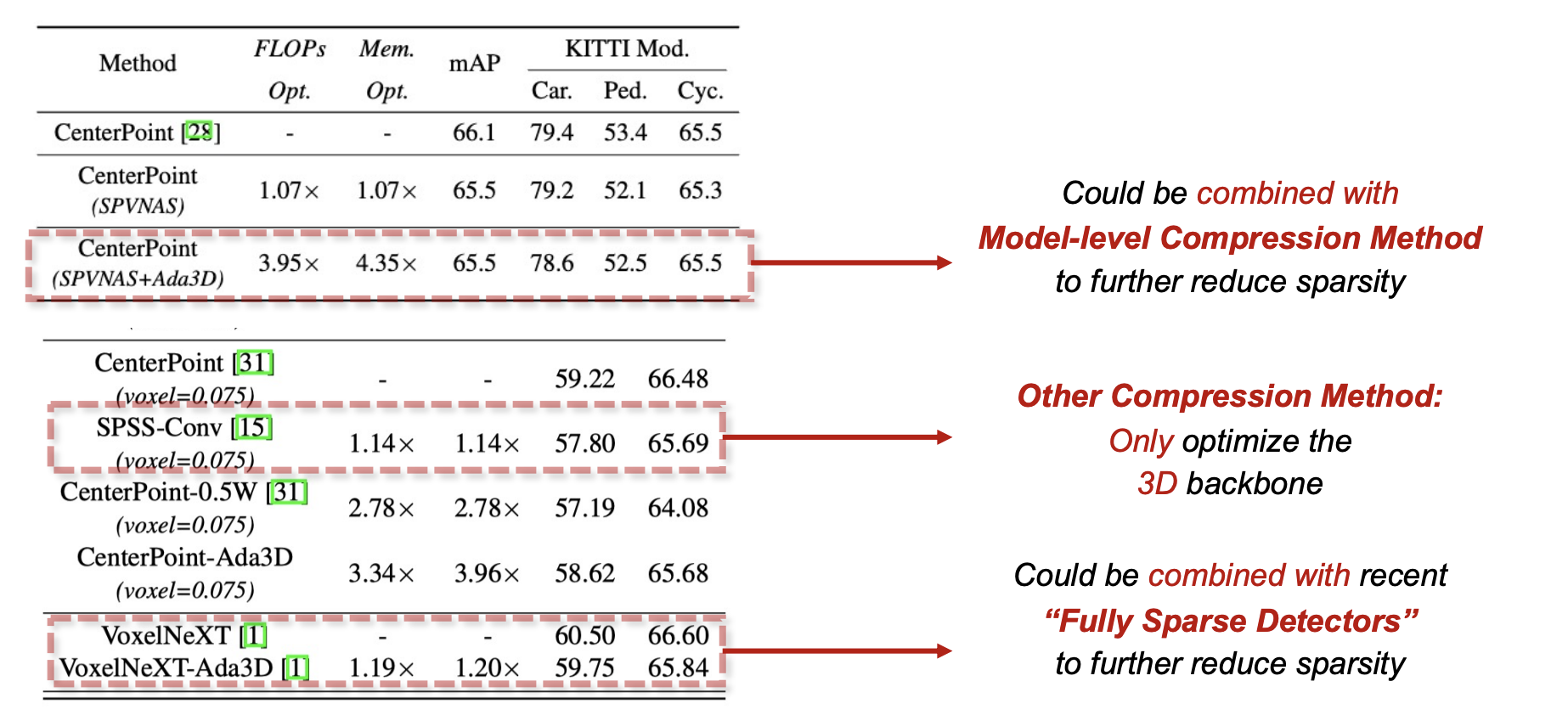
Comparison with other compression methods
Ada3D accelerates both the 3D and 2D backbone of 3D detector (some methods accelrates one of which only). Also, it could be combined with model-level compression methods (e,g, SPVNAS, VoxelNeXT).
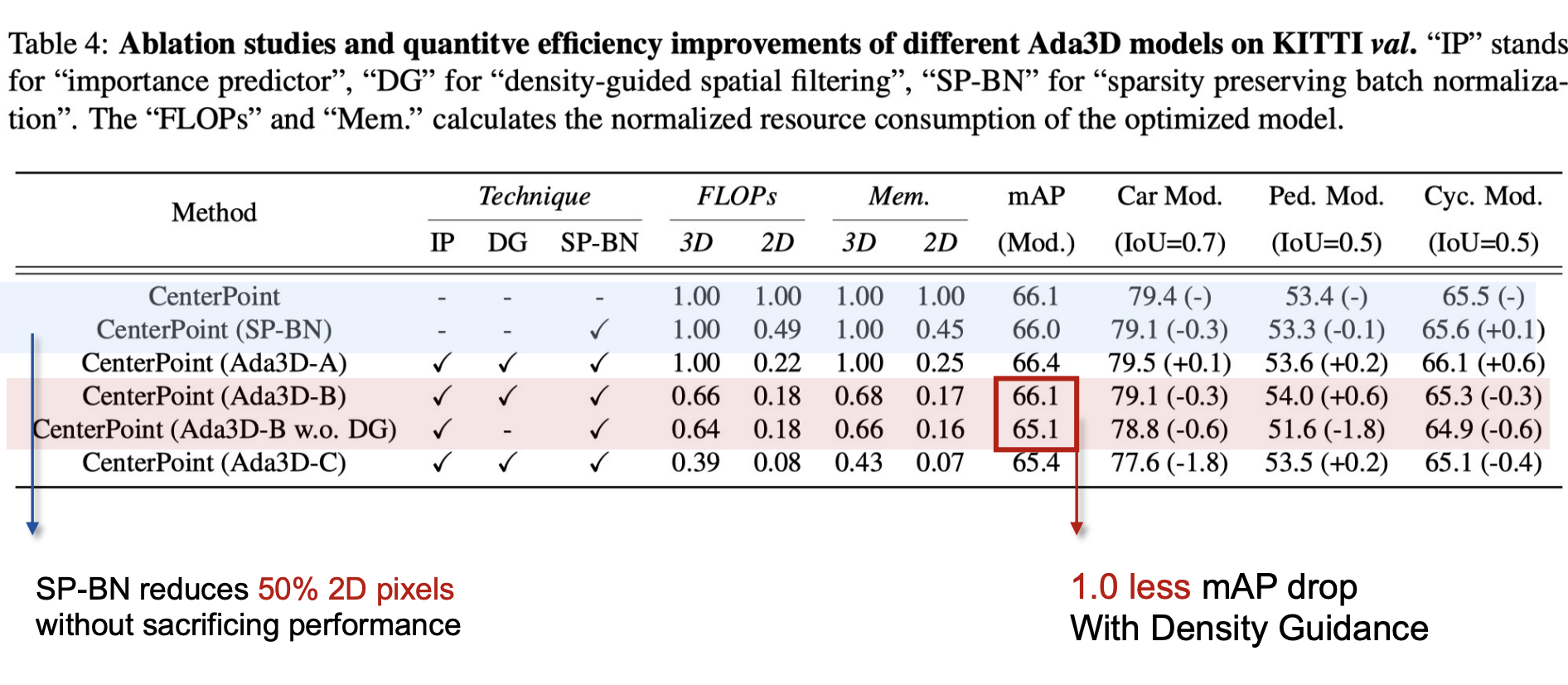
Ablation studies
Ablation studies is conducted to show the effectiveness of each techniques.
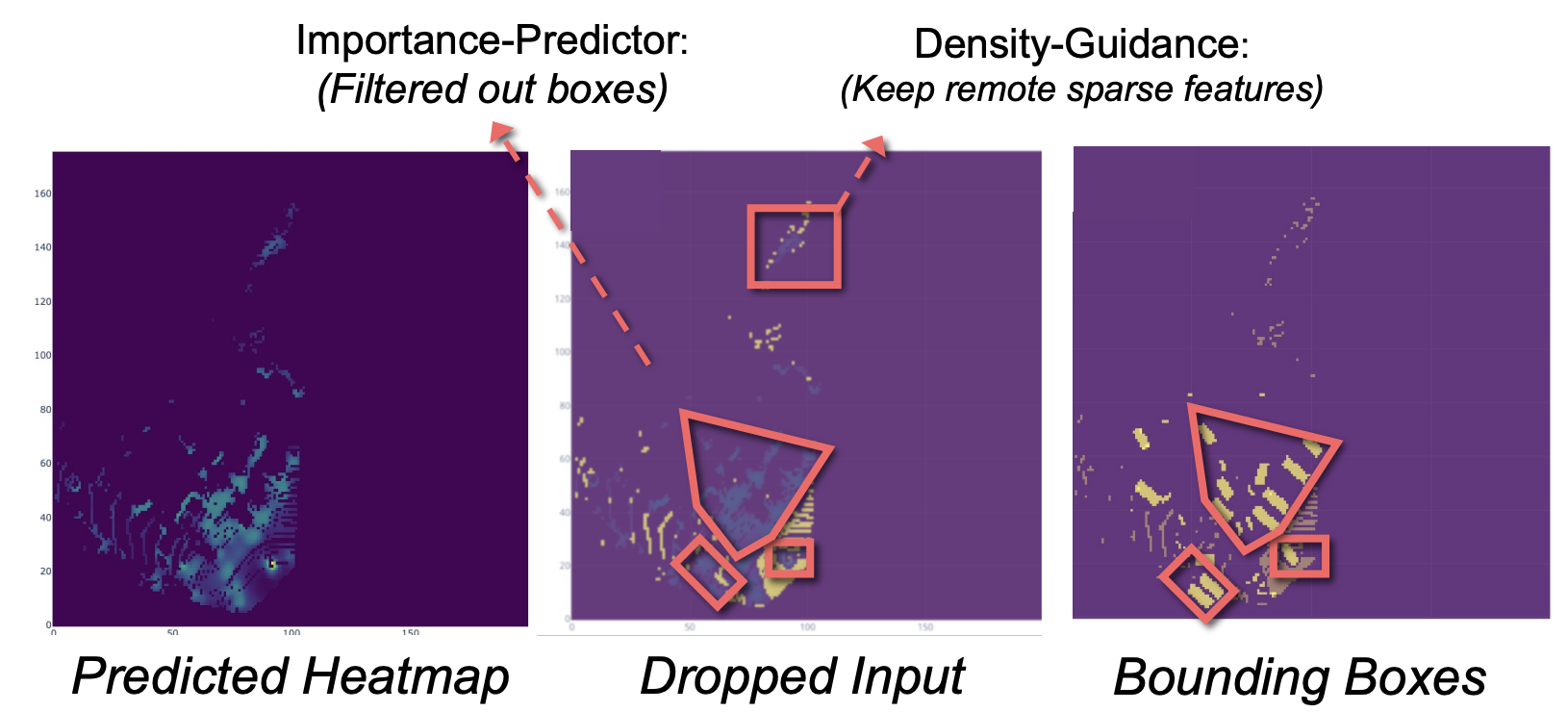
Effectiveness of Ada3D
The below visualizations demonstrate the effectiveness of Ada3D.

BibTeX
@article{Zhao2023Ada3DE,
title={Ada3D : Exploiting the Spatial Redundancy with Adaptive Inference for Efficient 3D Object Detection},
author={Tianchen Zhao and Xuefei Ning and Ke Hong and Zhongyuan Qiu and Pu Lu and Yali Zhao and Linfeng Zhang and Lipu Zhou and Guohao Dai and Huazhong Yang and Yu Wang},
journal={ArXiv},
year={2023},
volume={abs/2307.08209},
url={https://api.semanticscholar.org/CorpusID:259937318}
}